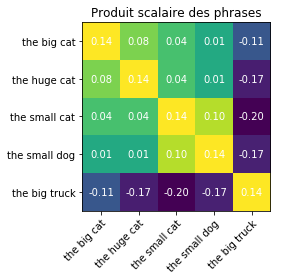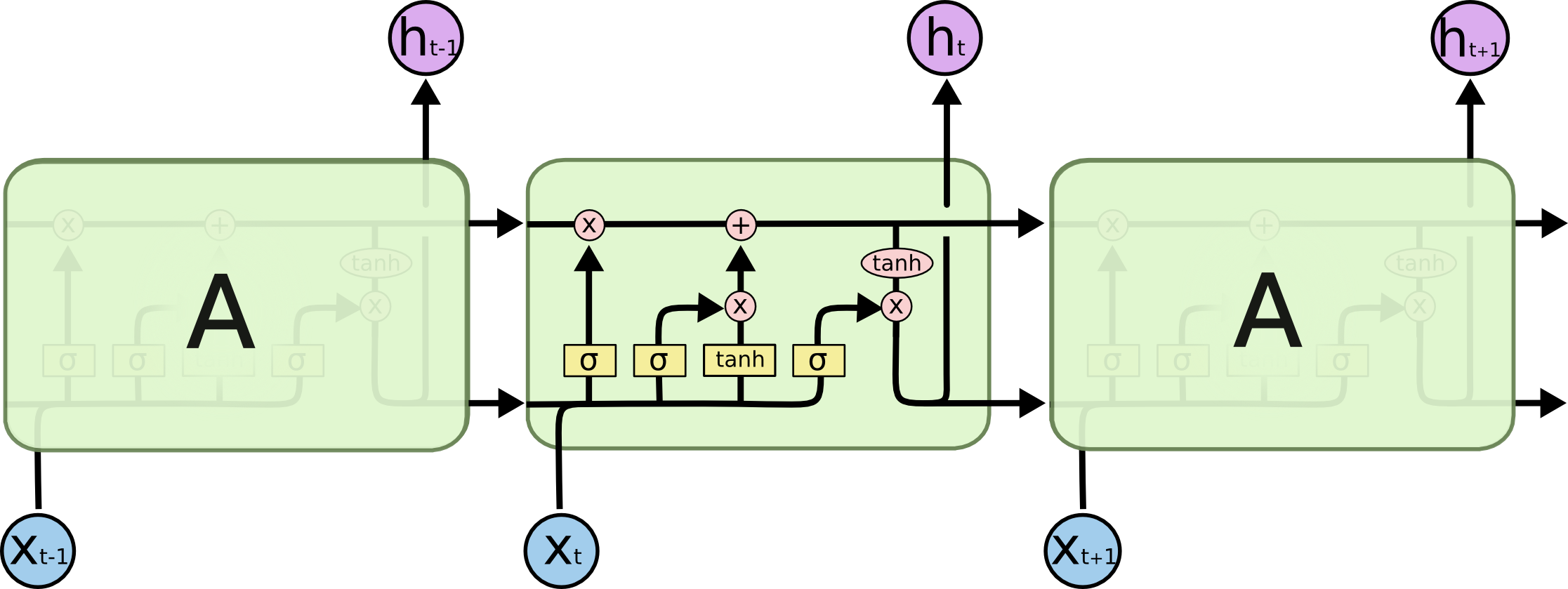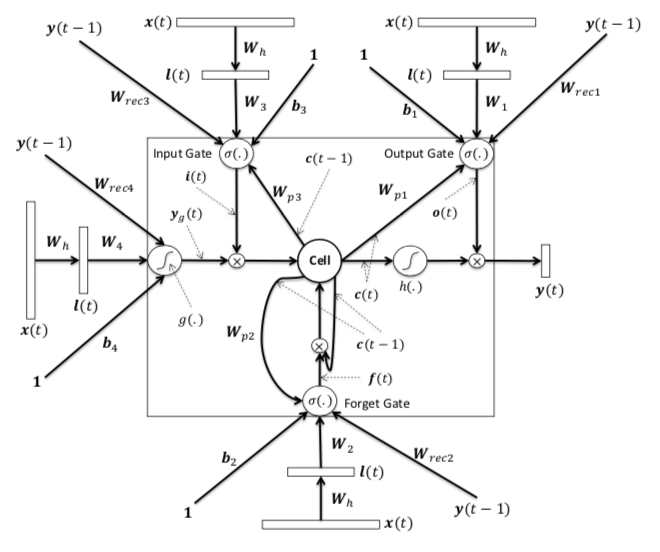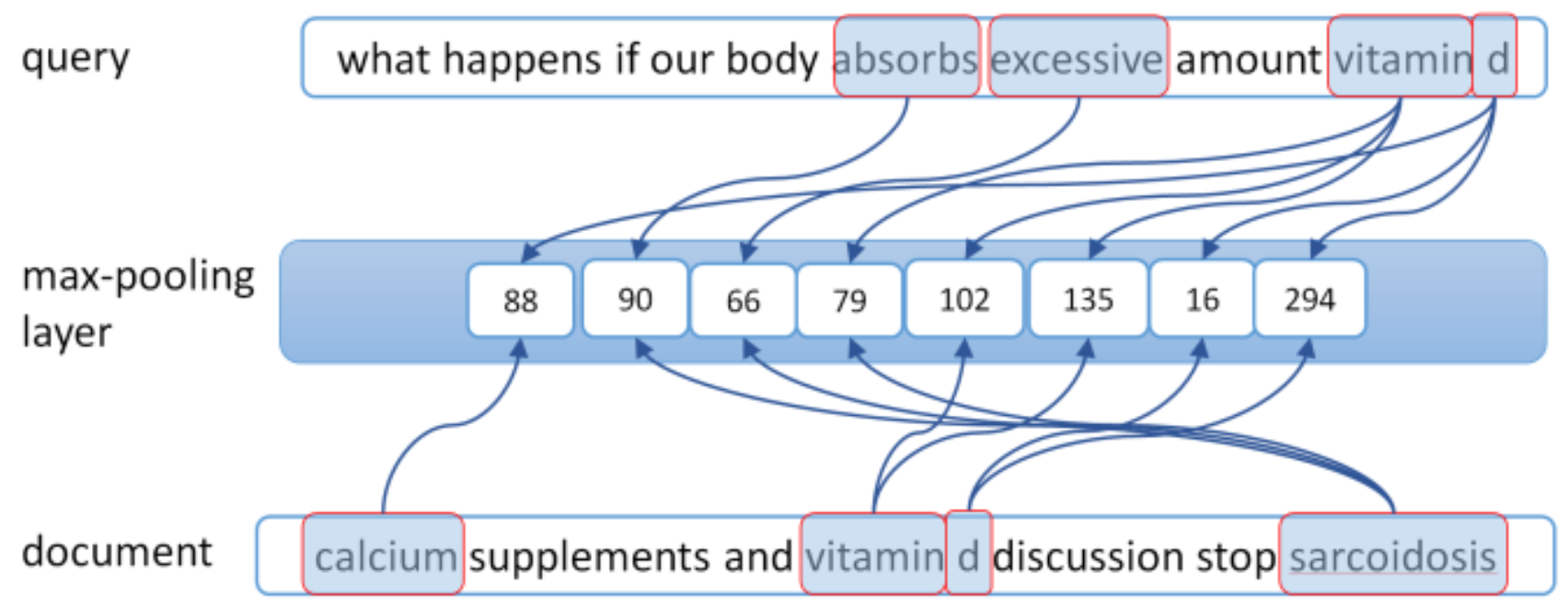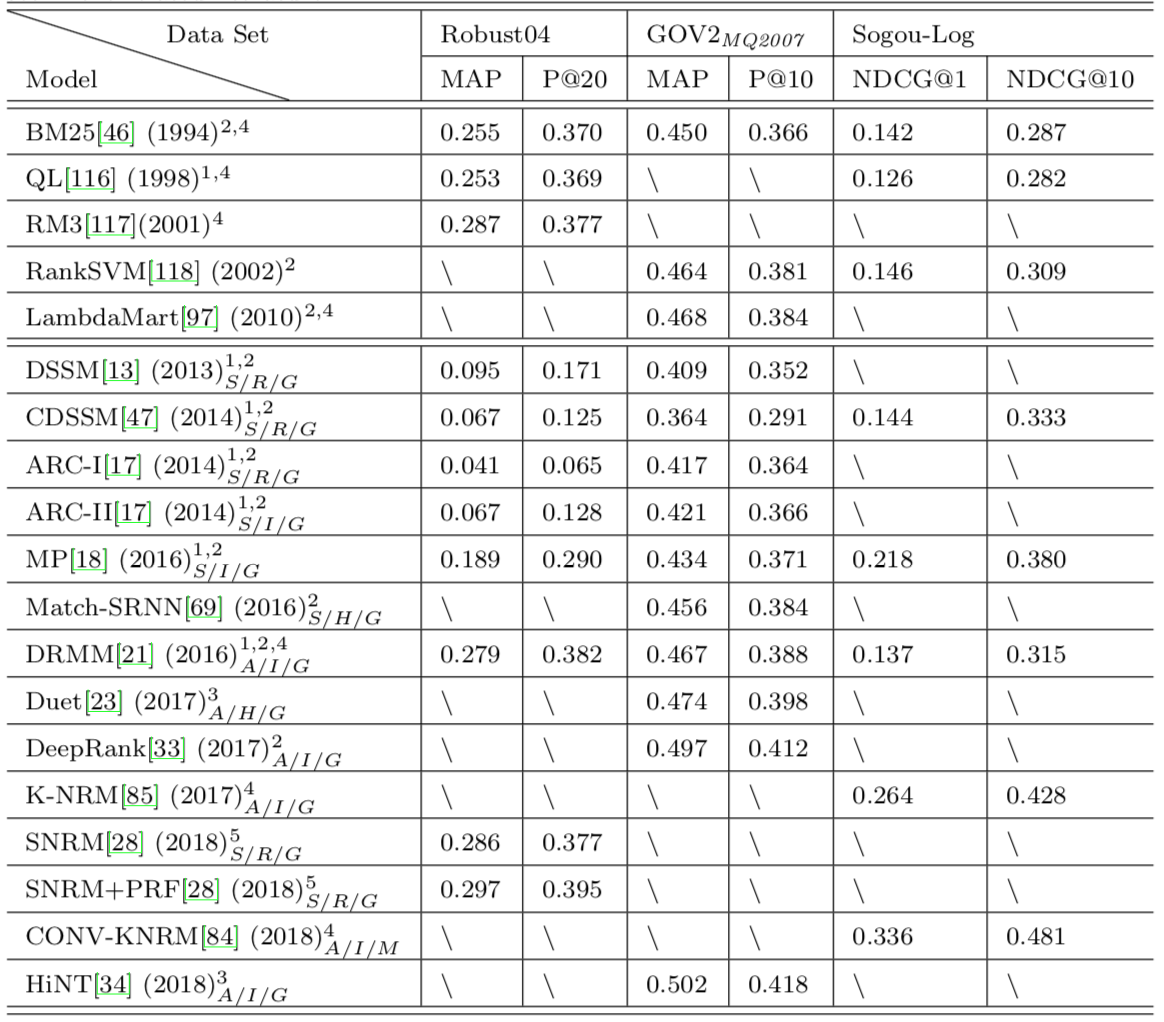
Le plus naturel ?
Grand vocabulaire
Mot inconnus




Particularités
Selon l'application, on peut utiliser l'un ou l'autre – ou les deux !
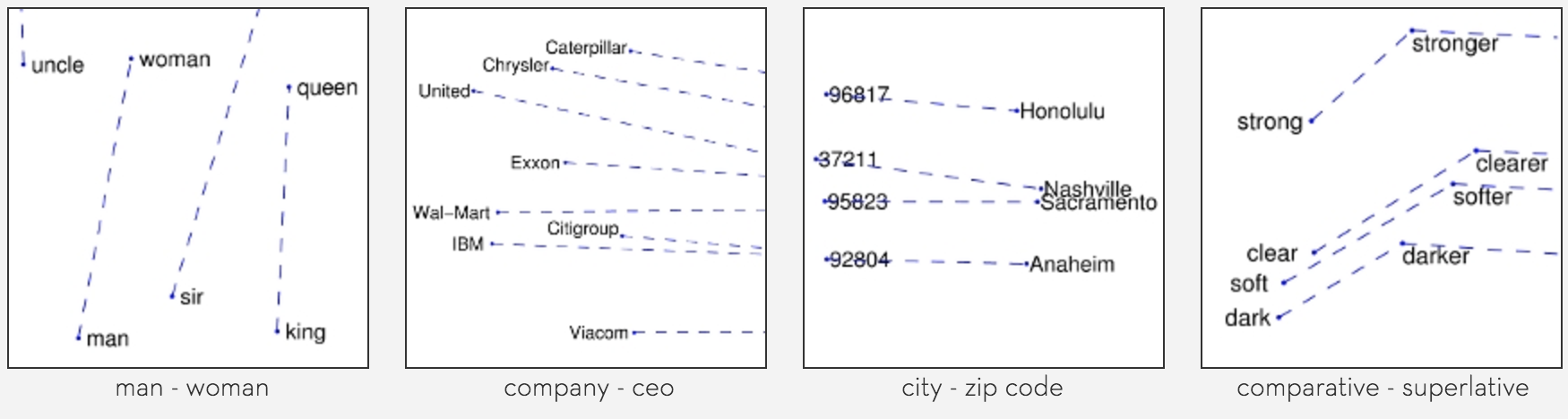
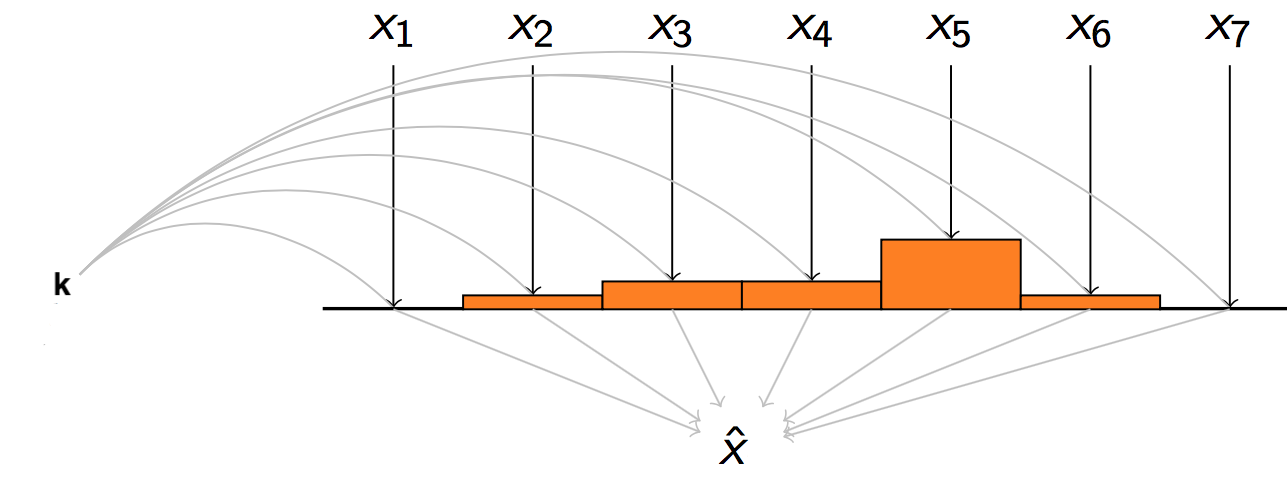
Apprendre en maximisant la vraissemblance sur des couples $(w,c)$ implique $$ x_w \cdot x_c = \frac{p(w, c)}{p(w)p(c)} - \log k$$
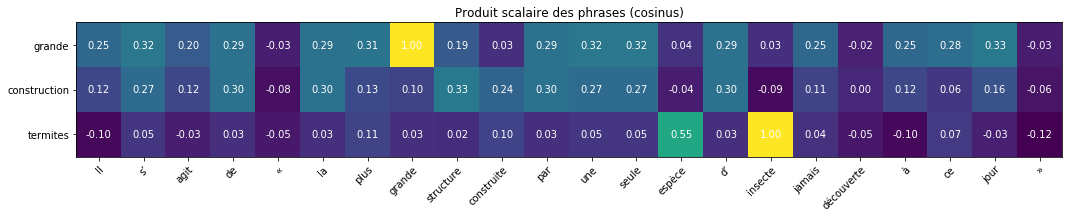
[ ▁les] [▁ter] [m] [ites] [,] [▁archite] [ctes] [▁bi] [oc] [li] [matiques]
Utilisation en RI
| mot 1 | mot 2 | mot 3 | mot 4 | ... |
| cl. 1 | cl. 2 | cl. 3 | cl. 4 | ... |
On classifie chaque mot dans la classe B (begin) | E (end) | I (intermediate) - Type
| Sophie | est | allée | boulevard | Jean | Jaurès |
| EB-Nom | NA | NA | B-Lieu | I-Lieu | E-Lieu |
Résultat
| mot 1 | mot 2 | mot 3 | mot 4 | ... |
| classe | ||||
On peut distinguer trois grandes classes d'approches
Dans le BIM (Binary Independance Model), on a
But: estimer $p(t|R, q)$
Idée du papier = $$p_u(v|d) \propto \cos(v, w) $$
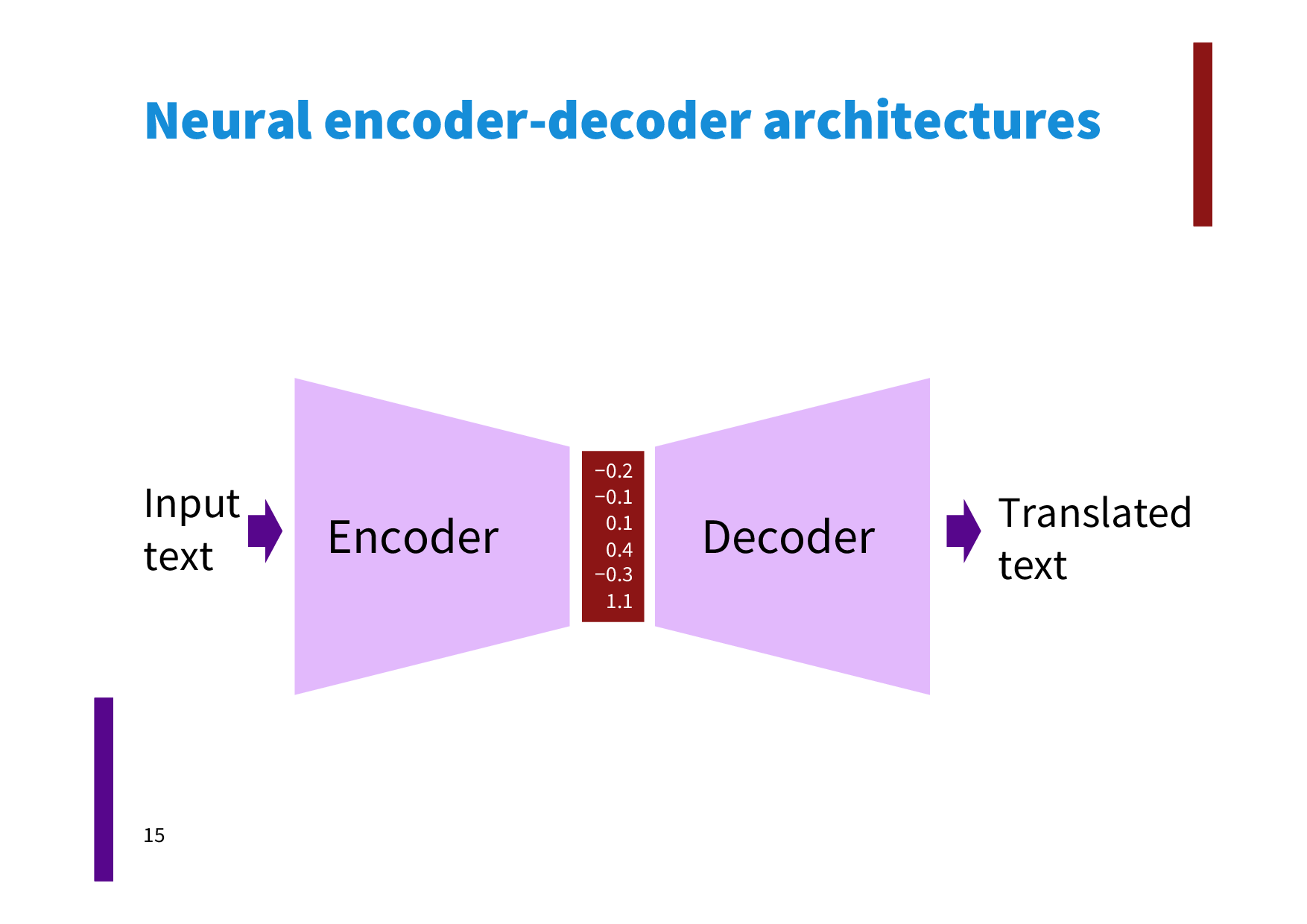
Point de départ: modèle de langue
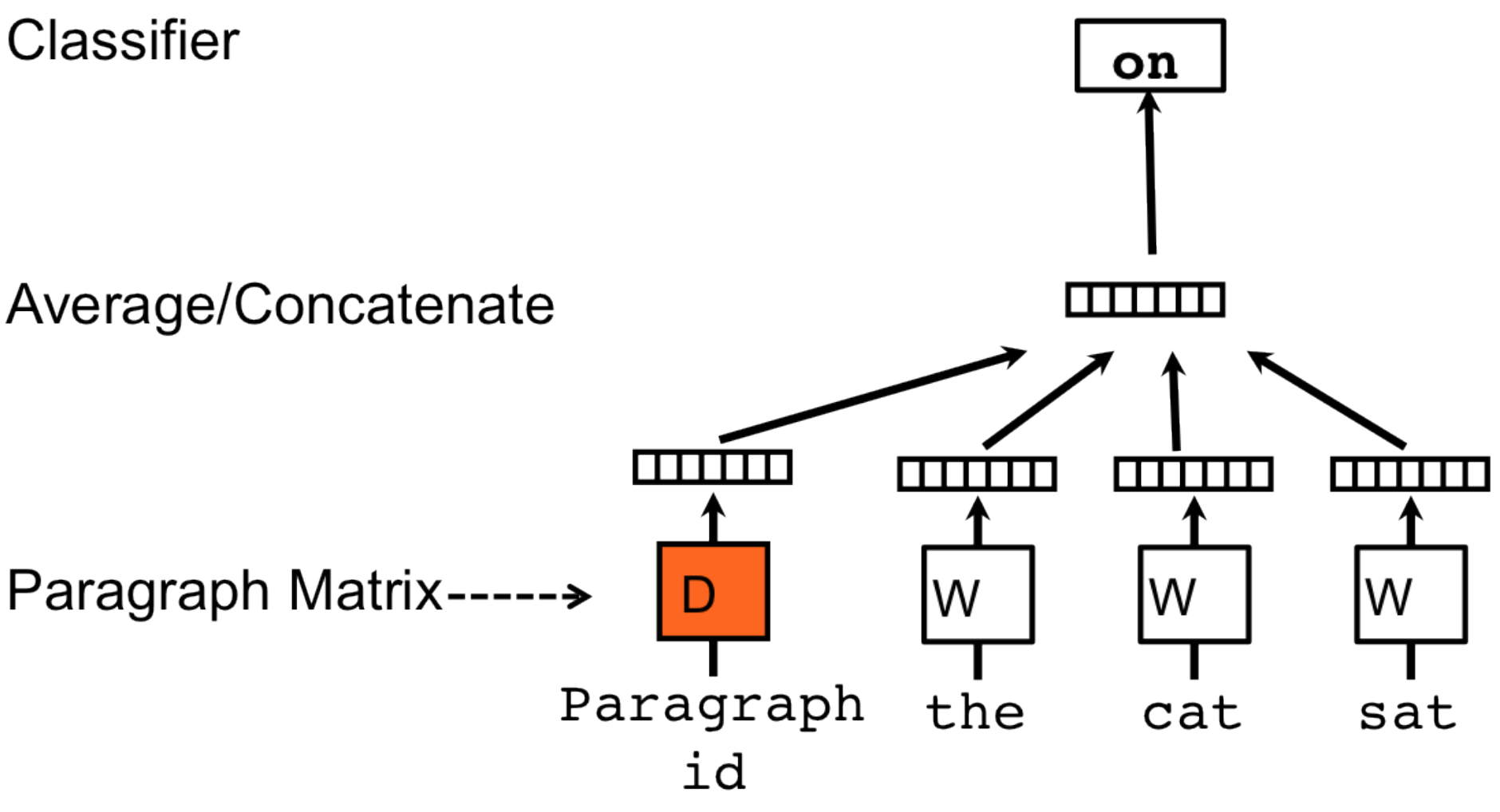
$$ p(w|d) = (1-\lambda) p_{QL}(w|d) + \color{red}{\lambda p_{PV}(w|d)} $$Une adaptation du modèle C-BOW (Word2Vec)
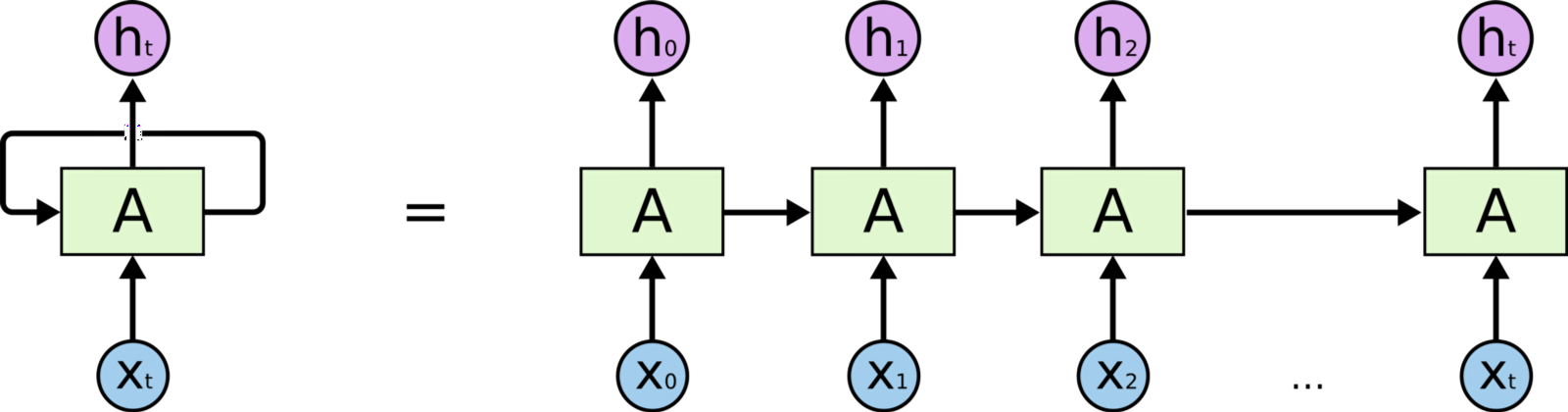
Utilisation d'unités avec des "portes"
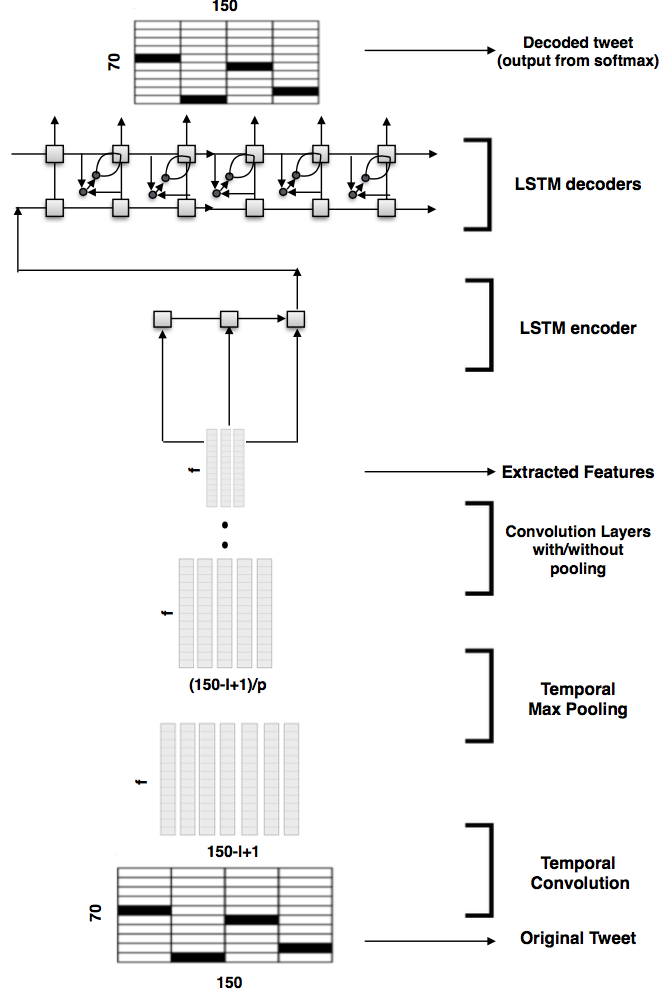
Vosoughi, S., Vijayaraghavan, P., & Roy, D. Tweet2Vec: Learning Tweet Embeddings Using Character-level CNN-LSTM Encoder-Decoder. SIGIR 2016
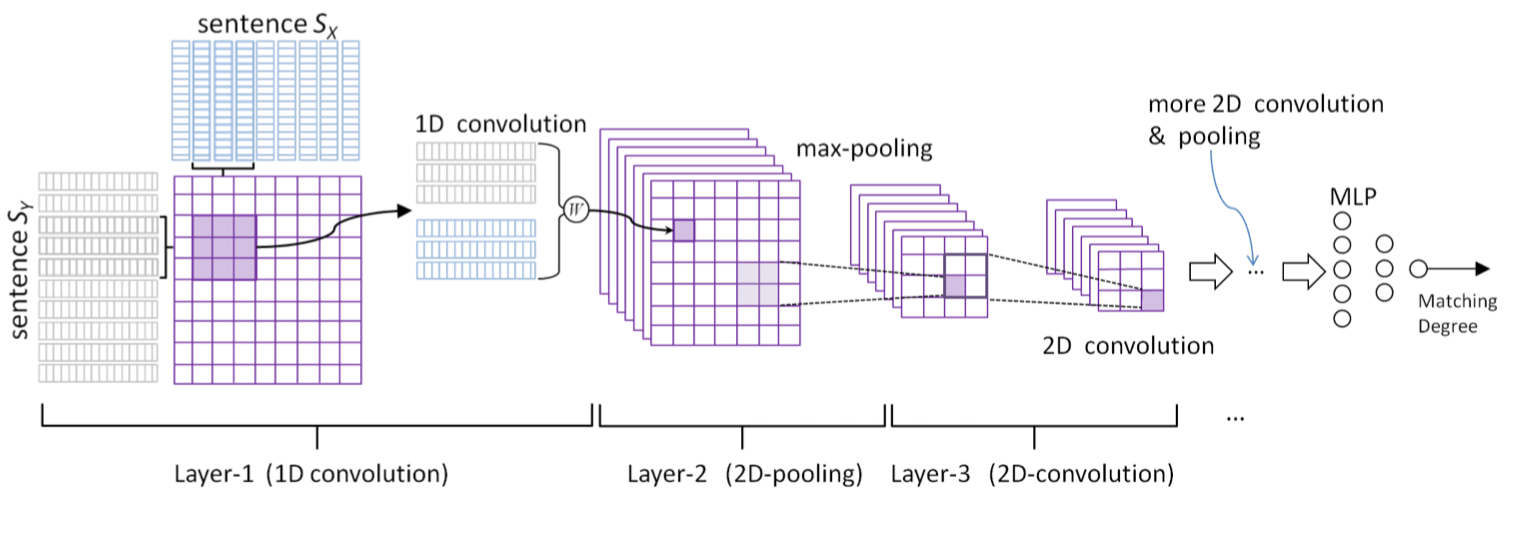
À chaque fois : invariance (1D, 2D) :
Opération répétée sur une sous partie de l'entrée
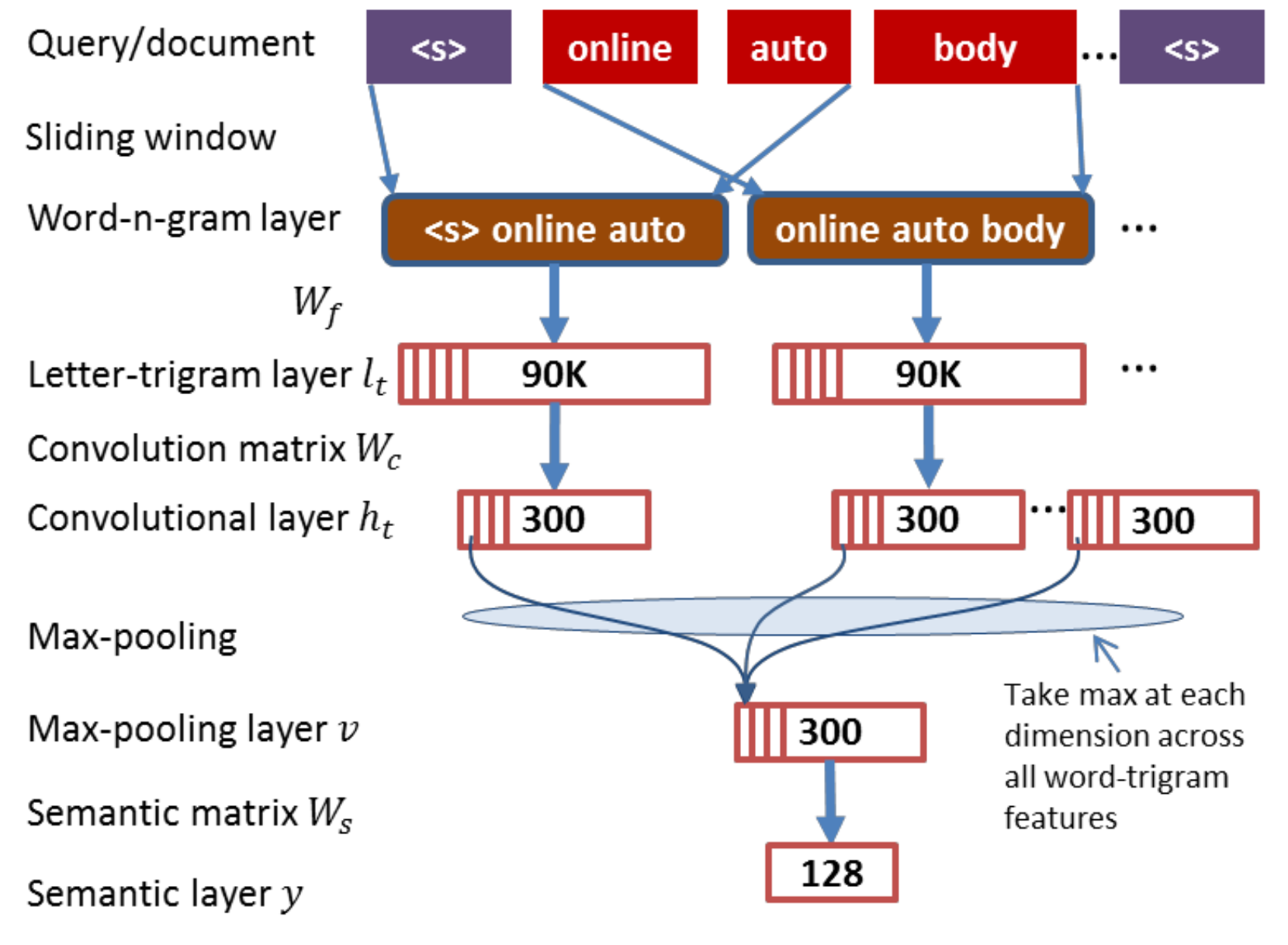
Shen, Y., He, X., Gao, J., Deng, L., & Mesnil, G. A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval. CIKM 2014.
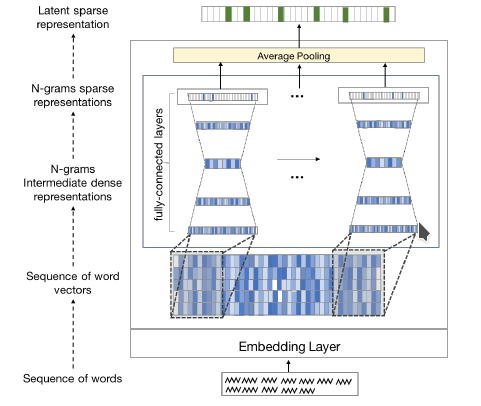
But : améliorer la capacité des réseaux de neurones à traiter des tâches complexes. Appliqué dans les tâches de question-réponse (entre autres)
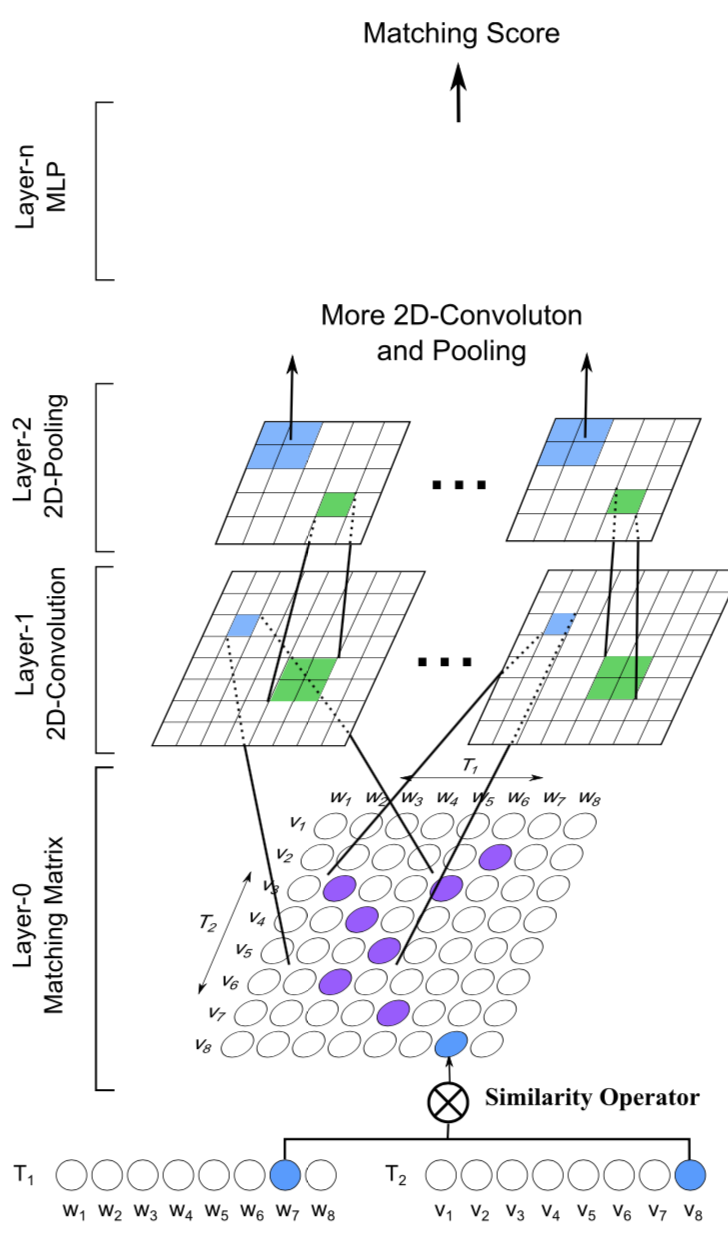
Experiments: QA Trec Dataset

On calcule sur l'ensemble de la base d'apprentissage $\mathcal D$
$$ \sum_{x \in\mathcal X} \Delta(x, f_\theta(x)) $$ où $\Delta$ mesure l'erreur par rapport à la sortie désirée en fonction de la tâche.L'ensemble d'apprentissage = paires entrée/sortie désirée $$ \mathcal D = \left\{ (x_i, \hat y_i) \right\} $$
Coût quadratique $$\Delta(f_\theta(d), \hat y) = \| y - \hat y\|^2$$
Applications : échelles ordinales
L'ensemble d'apprentissage = paires entrée / classe $c\in\{1, \ldots, k\}$ $$ \mathcal D = \left\{ (x_i, \hat c_i) \right\}_i $$
La fonction $f_\theta$ renvoie un vecteur $\mathbb R^k$, $$ f_\theta(x) = \left( p(c=1|x; \theta), \ldots, p(c=k|x;\theta) \right) $$
Coût cross-entropique $$ \Delta(f_\theta(x), \hat c) = \log p(c=\hat c | x; \theta) = \sum_{c} \Ind{c = \hat c} \log \left(f_\theta(x)\right)_{\hat c} $$
Applications
L'ensemble d'apprentissage = paires d'objet (ex. document) avec $x_+ \succ x_-$ $$ \mathcal D = \left\{ (x_i^+, x_i^-) \right\}_i $$ La fonction $f$ donne le score d'un objet
Application
Différents cas d'usage en fonction des données disponible et de la granularité du traitement
Données
Granularité